随着我国电子商务的飞速发展,网络营销已经越来越显示出它的强大和重要性。邮件和短信作为一种常规的营销推广手段,有很多的商家都在使用。但是如何有针对性的获取到本行业相关的用户的信息是当前主要的问题,有些商家从非正规渠道购买用户信息,我们暂且不讨论这里所涉及的隐私权的问题,但是我们知道,这些用户信息往往被多次转卖,信息的可靠性、时效性都无法保障。若是人工从互联网中搜索浏览并记录下客户信息,那么一方面由于这里的信息是公开的,基本不存在隐私争议;另一方面由于互联网信息更新速度快,信息的时效性也能有所保障。但是人工的成本高昂并且效率较低,因此我们希望开发出的软件能够代替人工实现类似的功能。
其实这一功能也就类似于搜索引擎的网页蜘蛛爬虫,它从互联网自动抓取采集数据,然后分析数据并保存所需要的信息。但是与常规的搜索引擎又有区别,在于这里的自动采集过程是有针对性的,不是基于站点之间的相互关联,也不是盲目的抓取所有页面的信息。
为了将过程简化,我们使用.net的HttpWebRequest对象来模拟一个浏览器请求,通过搜索引擎(Google,百度,雅虎,360,搜狗,搜搜)来筛选关键词。通过分析搜索引擎反馈页面及关联页面的信息来抓取采集所需要的数据。以google为例,创建的模拟请求代码如下:
try
{
HttpWebRequest request2 = (HttpWebRequest) WebRequest.Create("
http://www.google.com.hk/search?hl=zh-CN&newwindow=1&q=" + str +
"&start=" + i.ToString() + "&sa=N");
request2.Referer = "http://www.google.com.hk";
request2.Headers.Add("X_FORWARDED_FOR", "101.0.0.11");
request2.Method = "Get";
request2.KeepAlive = true;
request2.ContentType = "application/x-www-form-urlencoded";
request2.AllowAutoRedirect = true;
request2.Accept = "image/gif, image/x-xbitmap, image/jpeg, image/pjpeg,
application/x-shockwave-flash, application/vnd.ms-excel,
application/vnd.ms-powerpoint, application/msword, */*";
request2.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0;
Windows NT 5.1; SV1; .NET CLR 1.1.4322)";
CookieContainer container = new CookieContainer();
request2.CookieContainer = container;
responseStream = ((HttpWebResponse) request2.GetResponse()).GetResponseStream();
reader = new StreamReader(responseStream, Encoding.UTF8);
responseStr = reader.ReadToEnd();
responseStream.Close();
reader.Close();
}
catch
{
MessageBox.Show("网络请求异常,请稍候再试!");
return;
}
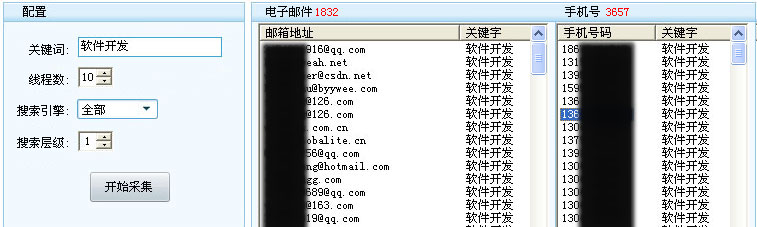
在智能爬虫获取到搜索页数据后,再分析和采集其中的网页地址数据,然后再请求以上地址页面。这里可以设置爬虫的抓取层级,若设置为1以上则继续以上过程抓取数据。我们这里测试时仅抓取1个层级的数据,然后将得到的信息以正则匹配的方式进行筛选,对于Email数据,正则表达式为\d[A-Z0-9._%-]+[@#]{1}[A-Z0-9._%-]+\.[A-Z]{2,4}\d。对于联系电话的正则表达式为(((13[0-9]|15[0|3|6|7|8|9]|18[6|8|9])\d{8})|^((\d{7,8})|(\d{4}|\d{3})-(\d{7,8})|(\d{4}|\d{3})-(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1})|(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1}))$))。提取到数据后就写入数据库,这里面可能会有重复数据,我们在后续处理中再剔除。
对于在对网页蜘蛛抓取到的信息进行简单的筛选和剔除重复数据后,就可以进行营销推广了。对于邮箱数据,可以采用.net的MailMessage对象发送邮件,但是需要注意的是,从实用的角度考虑,需要同时实现多个发送邮箱的设置切换及代理功能,否则单一邮箱可能被封。对于手机号数据,可以采用电信运营商所代理的Webservice调用来发送短信,具体的细节在此就不详述了。本工作室开发的模拟搜索引擎智能爬虫抓取程序测试效果如下: